Efficient Batch and Interactive LLM Inference at Scale with llm-d




As organizations deploy AI applications in production, their inference infrastructure must serve two fundamentally different workloads simultaneously: interactive requests requiring immediate replies, and batch inference jobs that process thousands of requests with a time tolerance of hours for receiving results. Use cases for batch inference include autonomous background agents performing multi-step reasoning and deep research, as well as user-initiated workloads like offline evaluations, dataset processing, and embedding generation.
In batch inference, the goal is to maximize throughput across a large volume of requests while meeting defined completion time targets, without interfering with interactive traffic. Non-urgent inference can fill GPU capacity during periods of lower interactive traffic, increasing infrastructure utilization. Users can also take advantage of differential billing between batch and interactive workloads for cost-optimized processing.
Batch Gateway brings first-class batch inference capabilities to llm-d. It provides an OpenAI-compatible API for submitting, tracking, and managing large-scale batch jobs, running efficiently alongside interactive inference workloads on shared infrastructure. With OpenAI API compatibility, users can migrate existing OpenAI batch scripts with minimal changes.
The challenge: batch and interactive workloads on shared infrastructure
When batch and interactive inference workloads compete for the same GPU resources without purpose-built tools, the outcomes are typically poor:
- Letting batch workloads degrade interactive performance is unacceptable for production services.
- Batch requests evict KV-cache entries needed by interactive workloads, forcing costly prefill reconstruction.
- Dedicating separate GPU pools for batch workloads is expensive and wasteful.
- Manually throttling batch workloads is operationally burdensome.
Batch Gateway is designed to solve this through built-in adaptive concurrency control and integration with llm-d's routing and scheduling components. Together, these mechanisms dynamically adjust batch flow based on available capacity, protect interactive traffic under load, and prioritize jobs based on SLO targets. The result is that batch jobs make steady progress toward their completion targets without interfering with interactive traffic.
Batch Gateway is production-grade, designed for shared multi-tenant environments where security, reliability, observability, and SLO compliance are essential.
Batch Gateway is part of llm-d, a CNCF Sandbox project and open source Kubernetes-native framework for high-performance distributed LLM inference. Batch Gateway integrates with llm-d's components, which means that batch workloads automatically benefit from llm-d's efficient inference capabilities, such as intelligent request routing, flow-control, and KV-cache reuse.
How Batch Gateway works
Batch Gateway is a Kubernetes-native system composed of several components:
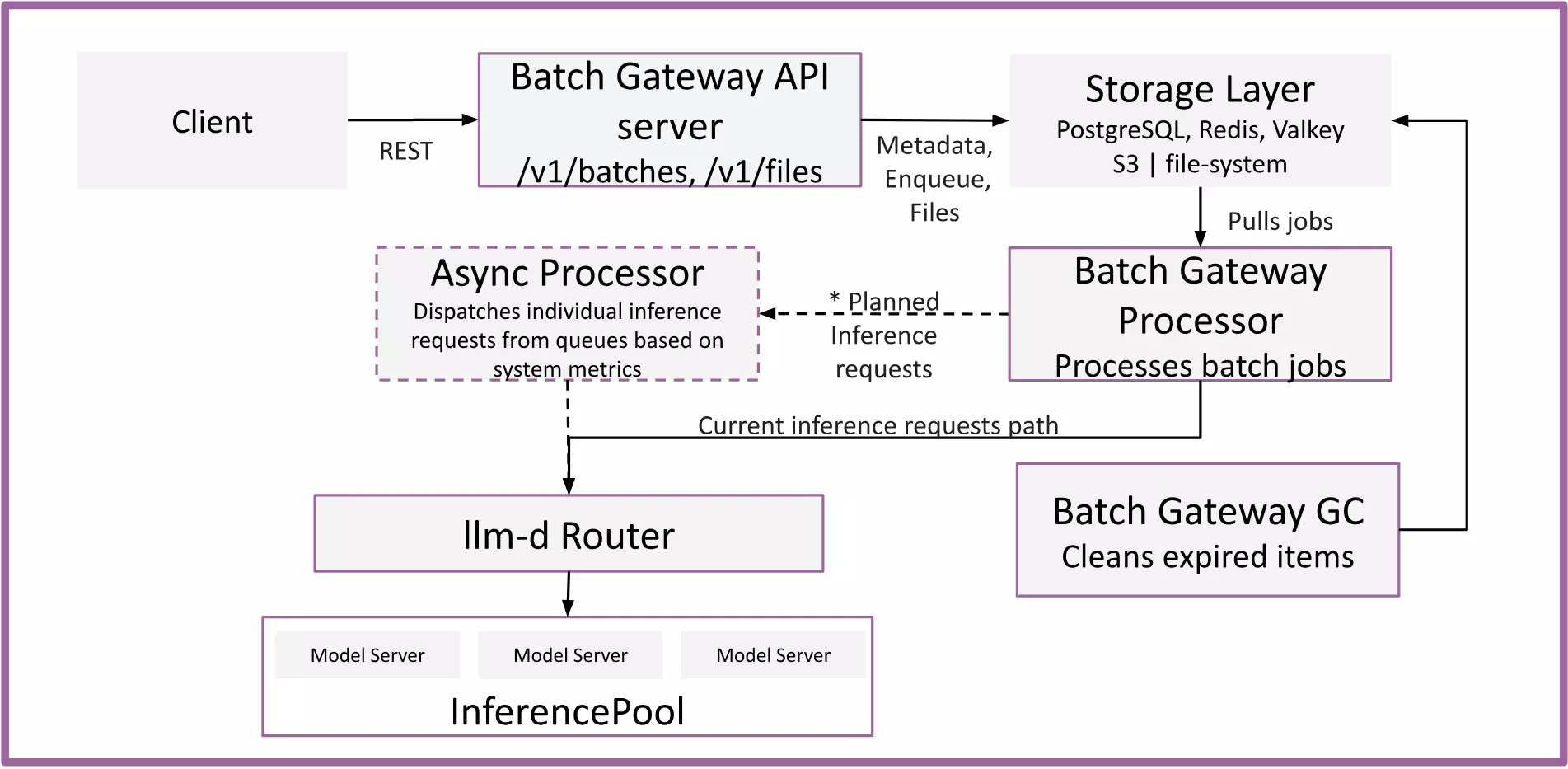
API Server
The API server exposes OpenAI-compatible /v1/batches and /v1/files endpoints, providing the same interface that users and applications already use for batch processing.
Data layer
Batch Gateway uses pluggable storage backends for different functions. Each function is backed by a single plug-in, chosen at deployment time.
| Function | Available plug-ins |
|---|---|
| Jobs and files metadata storage | PostgreSQL (for production), Redis, Valkey |
| Priority queue for jobs | Redis, Valkey |
| Event channels | Redis, Valkey |
| Jobs status updates | Redis, Valkey |
| File storage for input and output files | S3, Filesystem |
Expired batch jobs and their associated files are periodically cleaned up.
Batch Processor
The batch processor pulls jobs from a priority queue, retrieves the input files, builds execution plans, and dispatches individual inference requests concurrently for downstream processing. As inference results come back, the processor writes them to an output file, and continuously updates the job's status.
The processor sorts requests by system-prompt hash so that identical-prefix requests hit the inference engine contiguously, keeping cached prefix blocks hot and avoiding eviction-triggered prefill reconstruction. Combined with llm-d's prefix-cache-aware routing, cache reuse extends across the entire serving pool.
The processor listens for job events such as cancellation, enabling real-time control over in-flight work. In addition, the system handles recovery from crashes and failures during processing.
Getting started
To learn more about Batch Gateway, check out the following resources:
- To run a local demo of Batch Gateway using a kind cluster, check out the demo resources.
- To deploy Batch Gateway in a Kubernetes cluster using demo settings, see the demo deployment resources.
- For detailed deployment and setup instructions, check out the guide to deploy on Kubernetes.
- The project's documentation includes the main readme file, the guides, and design documents.
Get involved with llm-d
Batch Gateway is developed in the open as part of the llm-d ecosystem. If you're running LLM inference at scale and need batch processing capabilities, we'd love to have you involved.
- Explore the code -- Browse the Batch Gateway repo and the wider llm-d organization
- Join our Slack -- Get your invite and connect with maintainers and contributors
- Attend community calls -- All meetings are open! Add our public calendar and join the conversation
- Follow project updates -- Stay current on Twitter/X, Bluesky, and LinkedIn
- Watch demos and recordings -- Subscribe to the llm-d YouTube channel for community call recordings and feature walkthroughs
- Read the docs -- Visit our community page to find SIGs, contribution guides, and upcoming events